codfish #1: Building a Chess Engine
2026-04-15
Building codfish
I’ve been spending some of my free time trying to build and train a chess engine from scratch.
I’m calling it codfish, my small chess engine that I want to train to beat Stockfish someday.
I want to see how far I can get on a single GPU. From what I’ve seen so far, that looks pretty hard for chess, which makes it a good project. I’m aiming for something around 2500+ Elo.
There are also a few fun ideas I want to try along the way. One of the ones I keep thinking about is training one engine in an e4 e5 world and another in a d4 d5 world, then letting them play each other. I want to see if they grow into different kinds of players.
This series is just a record of that process. What I build, what fails, and what I learn from it.
The code is on GitHub at kevin-on/codfish.
Picking a starting point
I had to pick a starting point first.
The rough background is simple. AlphaGo was DeepMind’s system for Go. AlphaGo Zero removed human game data and learned through self-play. AlphaZero took the same basic idea and applied it to games like chess and shogi. Lc0, short for Leela Chess Zero, is an open-source chess engine built in the same general tradition.
I decided to start closer to AlphaZero than lc0. Mostly because it is simpler. lc0 already has a lot of strong ideas and practical improvements, but I wanted a smaller recipe that I could understand and debug end to end first.
The current recipe
Since this is a single-GPU project, I ended up making a few choices to fit that constraint.
Search
For search, I’m using Gumbel AlphaZero, from Policy Improvement by Planning with Gumbel.
The short version is that it is designed to work better when the search budget is small. That matters here because I do not have much compute to spend on search. On a bigger system, I would be more willing to just throw more simulations at the problem. Here I want something that still makes sense when that budget is tight.
Training loop
I’m also separating self-play and learning into different phases.
In larger systems, these usually run together. Self-play workers keep generating games, the learner keeps updating the model, and newer weights get sent back out to self-play as training moves forward. That makes sense when the main goal is throughput.
I’m not doing that right now. On one GPU, I would rather keep the loop simple: generate games, train on them, export a new model, then repeat. It is less efficient, but easier to run and easier to debug.
Targets
For targets, I’m borrowing one idea from lc0: predicting WDL instead of a single scalar value. The Lc0 AlphaZero primer is a good short reference.
The easiest way to think about it is this. An AlphaZero-style value head tries to summarize a position with one number, usually somewhere between -1 and 1. A WDL head keeps that prediction split into three parts: win, draw, and loss.
That matters because chess has a lot of draws. Two positions can both look like roughly 0 as a single scalar while meaning very different things. One might be sharp and unstable, like 45% win, 10% draw, 45% loss. Another might be quiet and close to dead equal, like 5% win, 90% draw, 5% loss. WDL keeps that difference visible.
Model
I’m interested in trying a small Chessformer-style model.
AlphaZero and older lc0 networks were built around convolutional ResNets. Chessformer applies a transformer to chess instead, and reports much better strength for its size. Recent lc0 work has also moved in that direction, so that is probably where I want to go too.
For now, though, this is still the toy stage, so I’m starting with a small ResNet.
Current status
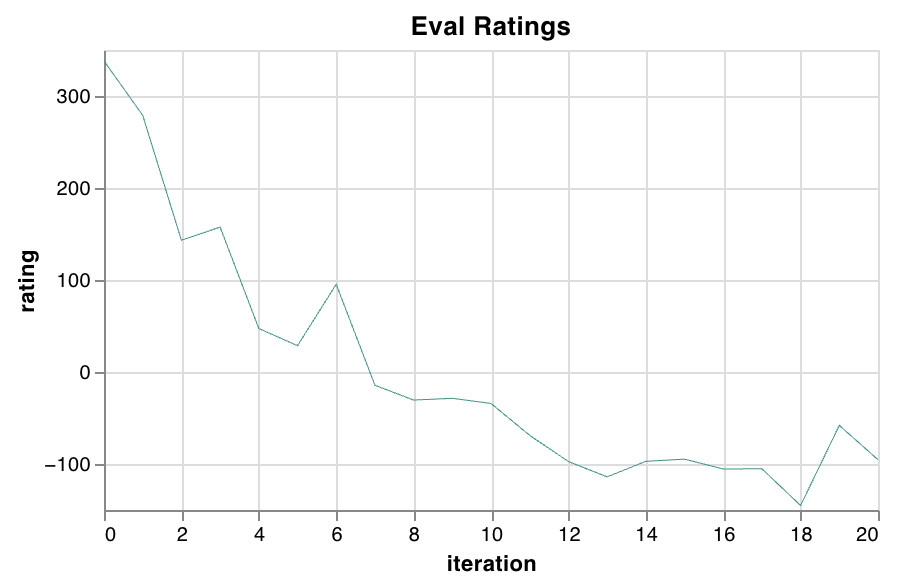
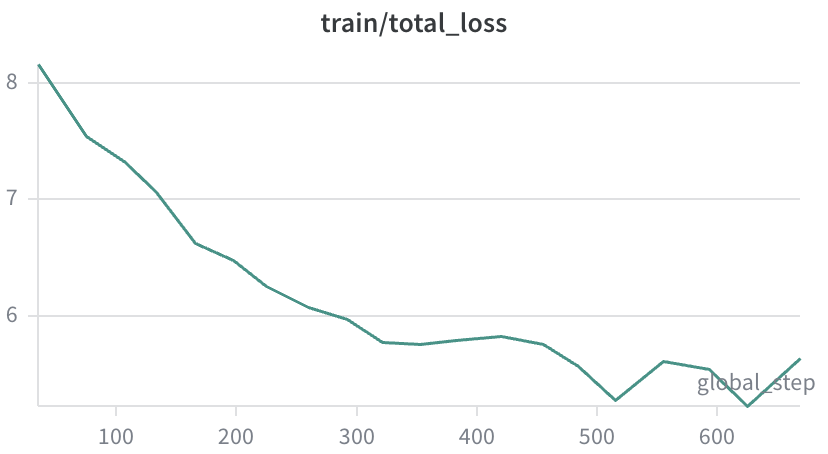
The pipeline runs end to end. It just doesn’t learn yet.
So far, Elo is worse than a random initialization. As training goes on, the model seems to develop an unhealthy preference for bishop moves. Games slowly turn into bishop shuffling, draws pile up, and improvement stops. The loss moves, but the playing strength does not.
I’ll come back to this after I’ve spent a bit more time debugging. Right now I understand the symptoms better than the cause.